※ 주의사항 ※
본 블로그는 수업 내용을 바탕으로 제가 이해한 부분을 정리한 블로그입니다.
본 내용을 참고로만 보시고, 틀린 부분이 있다면 지적 부탁드립니다!
감사합니다😁
인덱스(Index)
뷰(View)
스토어드 프로시저(Stored Procedure)
트리거(Trigger)
백업 및 복원 (Export & Import)
오늘 수업에는 테이블 외 데이터베이스의 개체들에 알아보고 활용하는 방법에 대해 배웠습니다.
수업은 My SQL을 통해 배웠으며 자습시간을 통해 Maria DB / SQL Server / Oracle DB로도 복습을 진행하였습니다.
1. 인덱스(Index)
1-1. 인덱스 개요

인덱스란 책의 제일 뒤에 있는 '찾아보기(색인)'과 같은 개념입니다.
책에서 어떠한 단어가 있는 위치를 찾기위해 책 맨 뒤의 색인을 찾아보고 해당 페이지를 찾는 것처럼
우리가 SELECT 등을 통해 데이터베이스안에 있는 어떤 특정한 데이터를 찾아보기 위해 인덱스를 거쳐서 찾게됩니다.
실습 처럼 데이터베이스의 양이 적을때는 인덱스의 효과가 미비하지만
실무에서는 데이터베이스의 양이 방대하기 때문에 인덱스의 사용유무의 차이는 속도적인 측면에서 아주 확연하게 차이가 나게 됩니다.
인덱스의 사용유무에는 정답이 없습니다.
DB의 사용 환경에 따라 결정이 됩니다. 예를들어 'shop_db'의 사용 환경이 INSERT가 많으면(ex. 회원가입) 인덱스는 사용하지 않고 SELECT가 많이 사용되는 DB의 경우(ex. 물품검색)에는 인덱스를 사용하는것이 좋습니다. (책의 뒷페이지에 색인을 만들어놨는데 중간에 페이지가 추가되면 색인이 맞지 않는 경우와 일치한다 볼 수 있습니다.)
통상적으로는 테이블의 열마다 인덱스를 만들 수 있지만 많이 조회하는 열에 만드는것이 좋고,
특히 WHERE절에 있는 열로 인덱스를 하고 SELECT 뒤에 나오는 열로는 인덱스를 안하는것이 좋습니다.
자세한건 아래의 실습을 통해 확인해보도록 하겠습니다.
1-2. 인덱스 실습
먼저 인덱스를 실습하기위해 world라는 데이터베이스의 테이블을 확인해 보겠습니다.
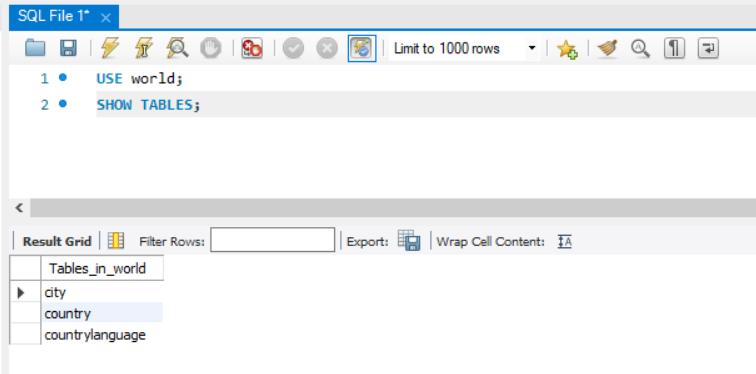
SHOW '테이블명' 을 통해 3개의 테이블이 존재하는것을 확인해봤습니다.
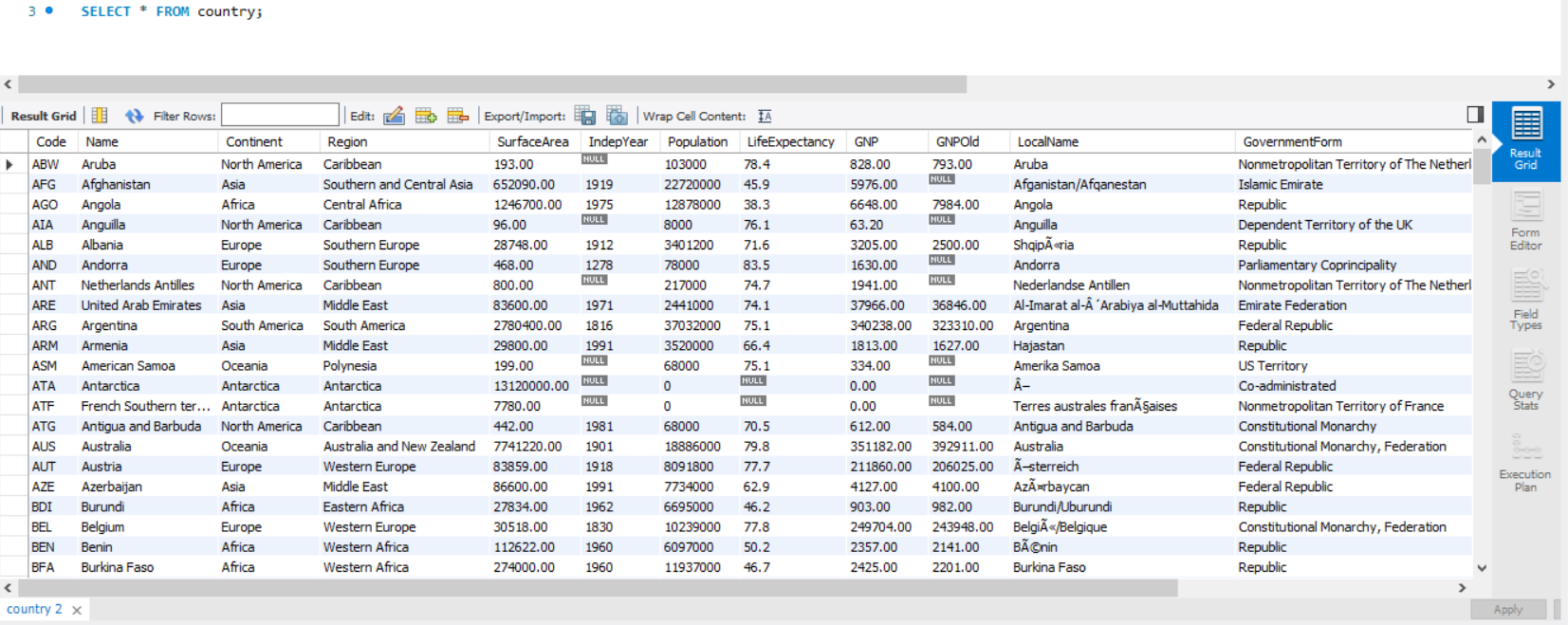
그러면 country 테이블에서 인덱스가 없는 쿼리문이 어떻게 실행되는지 확인해보겠습니다.
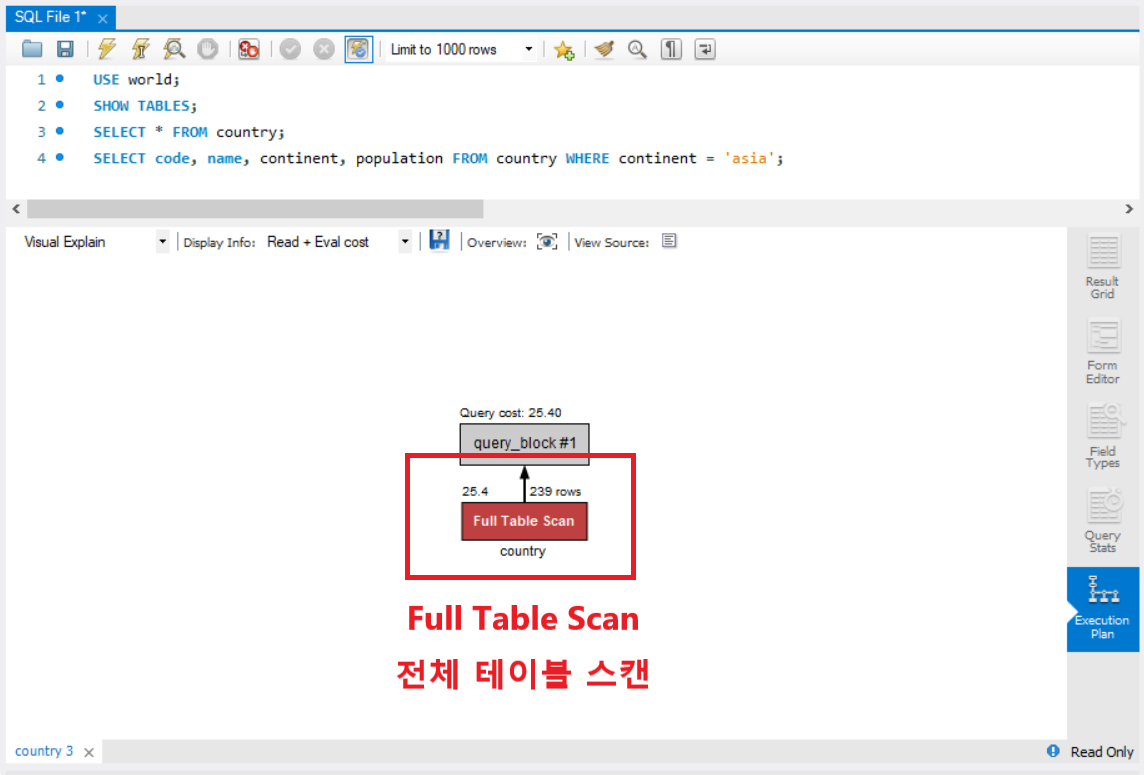
인덱스를 사용하지 않고 수행한 쿼리문의 경우 실행계획에서
'Full Table Scan' 즉 , 해당 SELECT문을 수행하기 위해 전체 테이블을 검색해서 처리하였다고 나옵니다.
그렇다면 인덱스를 사용하고 수행한 쿼리문은 실행계획에서 어떻게 표시될까요?
먼저 인덱스를 생성해보겠습니다. (인덱스 제거는 다른 예약어와 동일하게 DROP을 사용하면 됩니다. DROP INDEX INDEX명 ON 테이블명)
CREATE INDEX idx_continet_country ON country(continent); --> 인덱스 생성
-- DROP INDEX idx_continet_country ON country; --> 인덱스 제거위의 개요에서 인덱스는 SELECT 뒤의 열이 아닌 WHERE문의 열로 생성하는것이 좋다고 언급을 하였었습니다.
따라서 country 테이블의 continent 열로 인덱스를 생성했습니다.
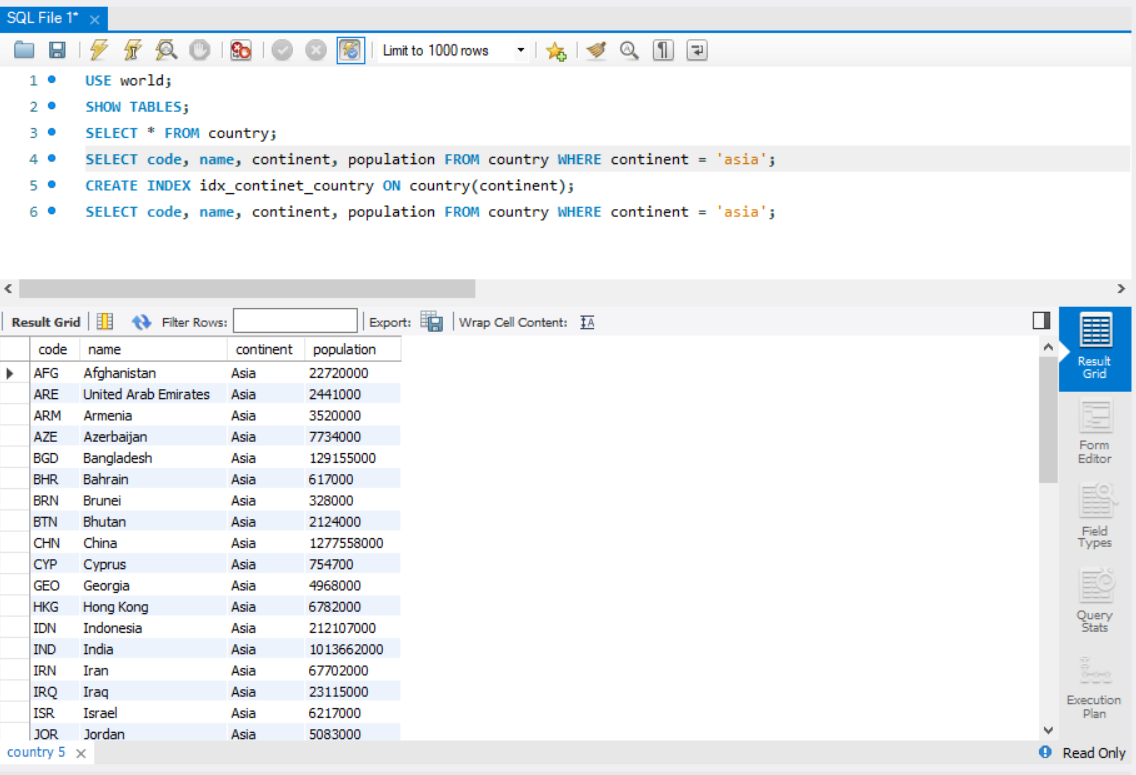
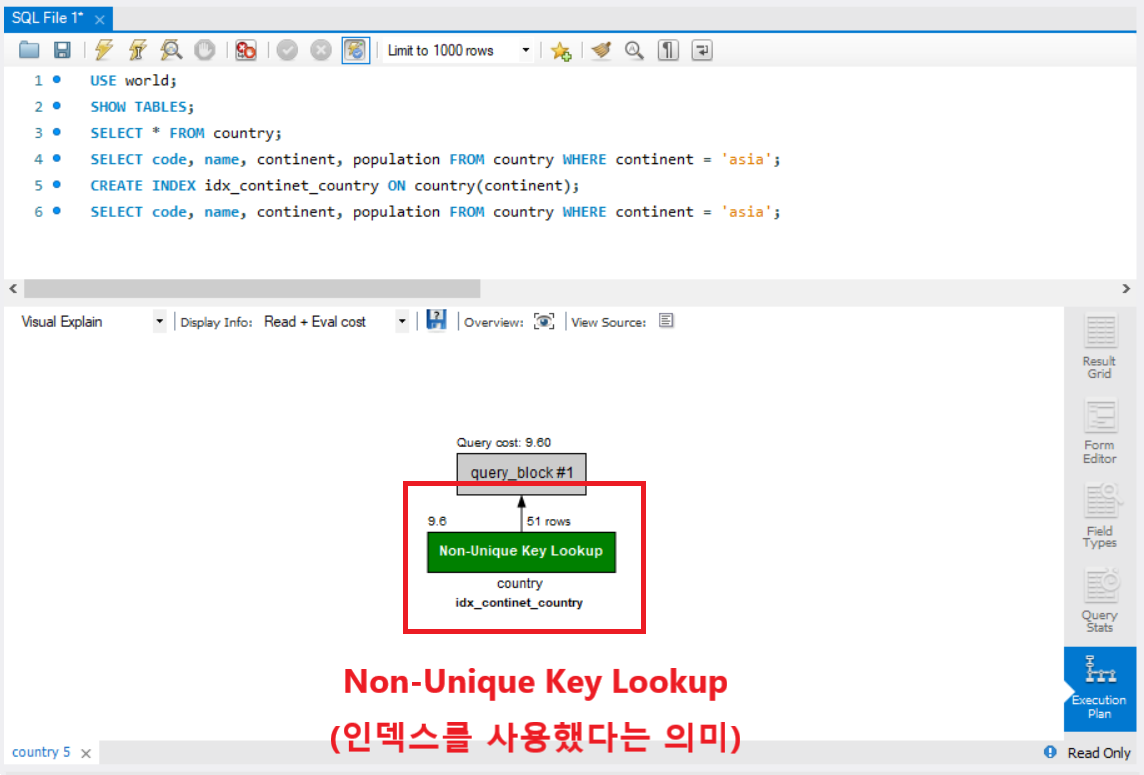
동일한 SELECT문을 사용했기 때문에 출력테이블의 결과는 인덱스 사용전과 동일합니다.
하지만 실행계획을 보면 Full Table Scan 에서 Non-Unique Key Lookup으로 바뀐것을 확인 할 수 있습니다.
이는 인덱스를 사용하여서 SELECT문을 수행하였다고 생각하면 될 것 같습니다.
참고로 사용 DB마다 인덱스를 거쳐서 쿼리문이 실행됐는지 확인하는 방법은 각기 다릅니다. 따라서 관련 책이나 서칭을 통해 해결해야할 것 같습니다.
※ WHERE절에서 LIKE 사용시 주의할 점!! ※
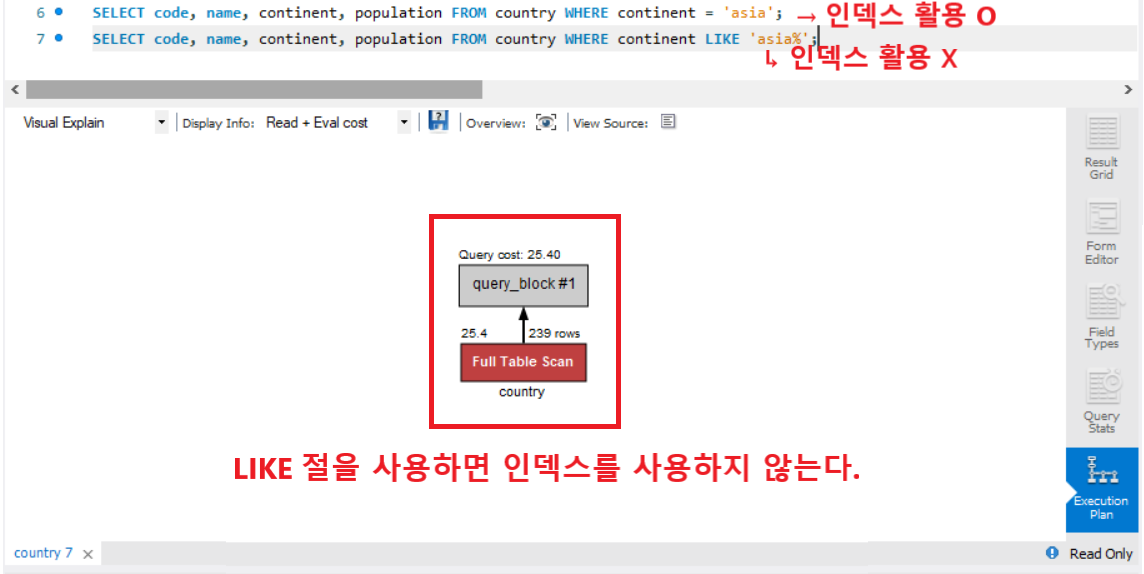
제목이나 내용을 검색하기 위해 WHERE 뒤에 LIKE를 많이 사용하는데 LIKE절은 열안에 데이터를 확인해야하기 때문에 무조건 Full Scan이 이루어 집니다. 따라서 LIKE절은 인덱스를 거쳐가지 않습니다!!
2. 뷰(View)
2-1. 뷰 개요
뷰는 가상의 테이블 입니다. 그리고 그 가상의 테이블은 진짜 테이블에 링크(Link)되어 있습니다.
뷰를 사용해서 가상의 테이블을 만들면 진짜 테이블을 조회하게 되는것과 동일한 결과를 얻게 됩니다.
따라서 가상의 테이블을 만들어서 데이터를 수정하게 되면 진짜 테이블의 동일한 데이터가 수정됩니다.
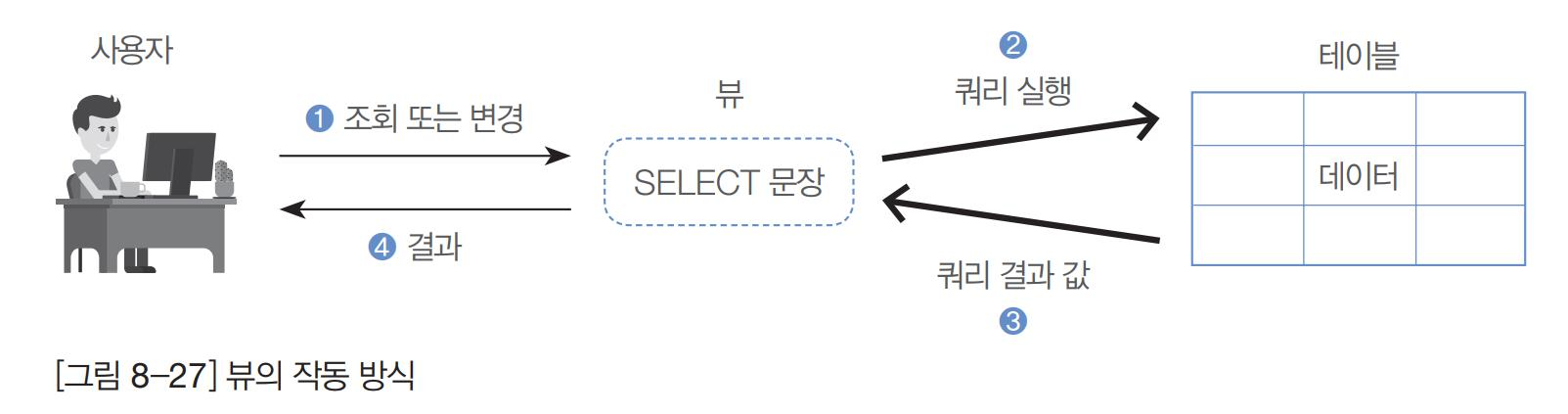
그렇다면 이 뷰는 실무에서 어떻게 적용되고 사용되게 될까요??
개인정보와 같이 민감한 데이터들은 접근하는 사람이 적을수록 유출되는 확률이 적어집니다. 그러기 위해서 이러한 민감한 데이터들은 제외하고 가상의 테이블을 만듬으로써 좀 더 많은 사용자가 데이터베이스에 접근할 수 있게 됩니다. (물론 개인정보의 유출에 대한 걱정 없이!!!)
2-2. 뷰 실습
뷰를 실습하기위해서 sakila 데이터베이스의 customer 테이블을 확인해 보겠습니다.
크게 민감한 정보는 없지만 굳이 따지면 email 주소가 민감한 정보에 속하겠군요!?
그렇다면 이러한 email 주소를 제외하고, 이름과 고객아이디만 열로 뷰를 만들어보겠습니다.
CREATE VIEW view_customer
AS
SELECT customer_id, first_name, last_name FROM customer;customer 테이블에 있는 customer_id, first_name, last_name을 가지고 view_customer 이란 가상의 뷰를 만들겠다는 쿼리문입니다.
그러면 실제로 해당 뷰를 확인해볼까요? 제가 원하는 열만 포함되어 있는지 보겠습니다.
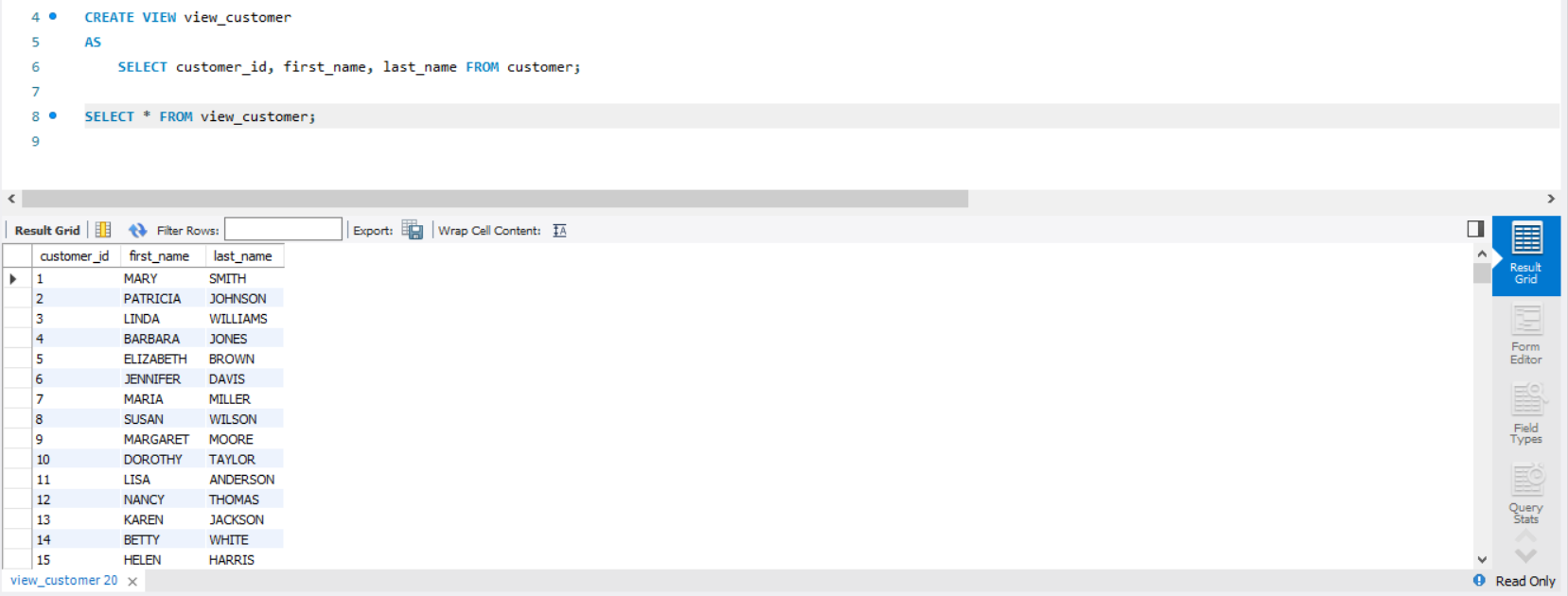
이렇게 VIEW문 안에 CREATE 절에 속한 열만 포함되어 있는 가상의 테이블이 생성되었습니다.
그렇다면, 실제로 이 가상의 테이블(view_customer)과 실제 테이블(customer)이 연결되어있는지 확인해보겠습니다.
UPDATE view_customer SET first_name = 'youngha' WHERE last_name = 'SMITH';last_name이 'SMITH'인 행의 first_name을 'youngha'로 수정하고 실제 테이블에 어떻게 적용되었는지 보겠습니다.
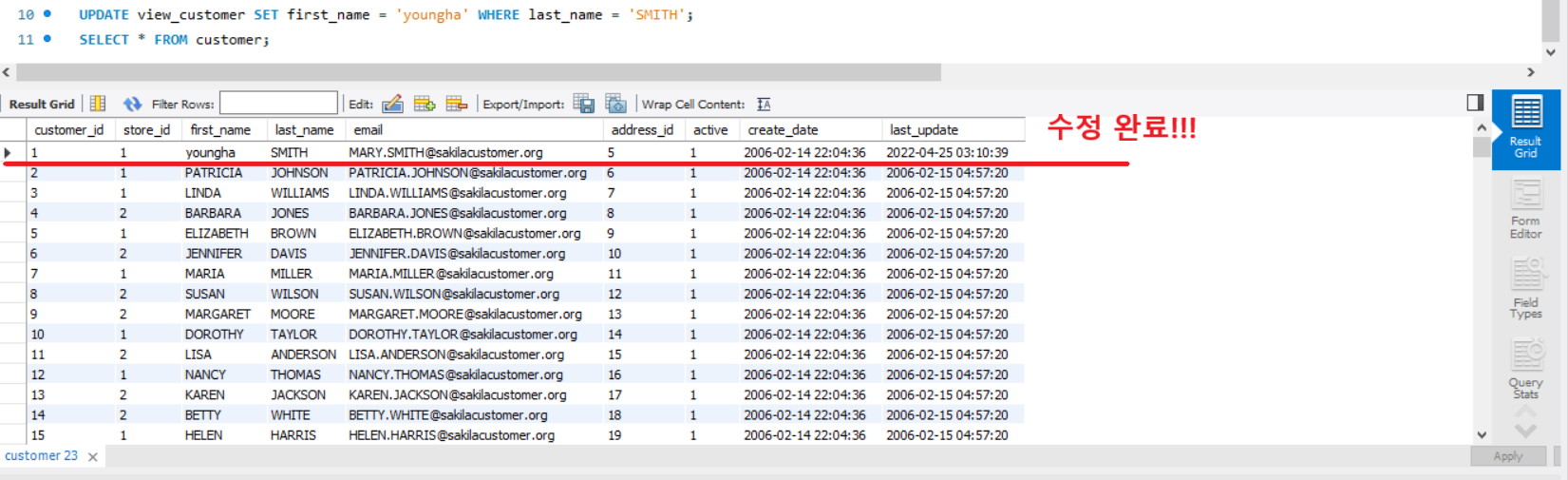
UPDATE를 통해 가상의 테이블(view_customer)을 수정했는데 실제 테이블(customer)의 데이터가 수정된것을 확인할 수 있었습니다.!!
3. 스토어드 프로시저(Stored Procedure)
3-1. 스토어드 프로시저 개요 및 실습
스토어드 프로시저란 My SQL에서 제공해주는 프로그래밍 기능을 의미합니다.
SQL문을 하나로 묶어서 편리하게 사용하는 기능입니다. (다른 프로그래밍 언어와 같은 기능을 담당할 수 도 있음)
실무에서는 주로 SQL문(SELECT 문)을 매번 하나하나 실행하기 보다는 스토어드 프로시저를 만들어 놓은 후에 호출하는 방식으로 사용합니다.
여태까지 배운 SQL문을 활용해서 두개의 서로다른 테이블을 호출할려면 어떻게 해야할까요??
아마 아래와 같은 방식으로 호출할 것입니다.
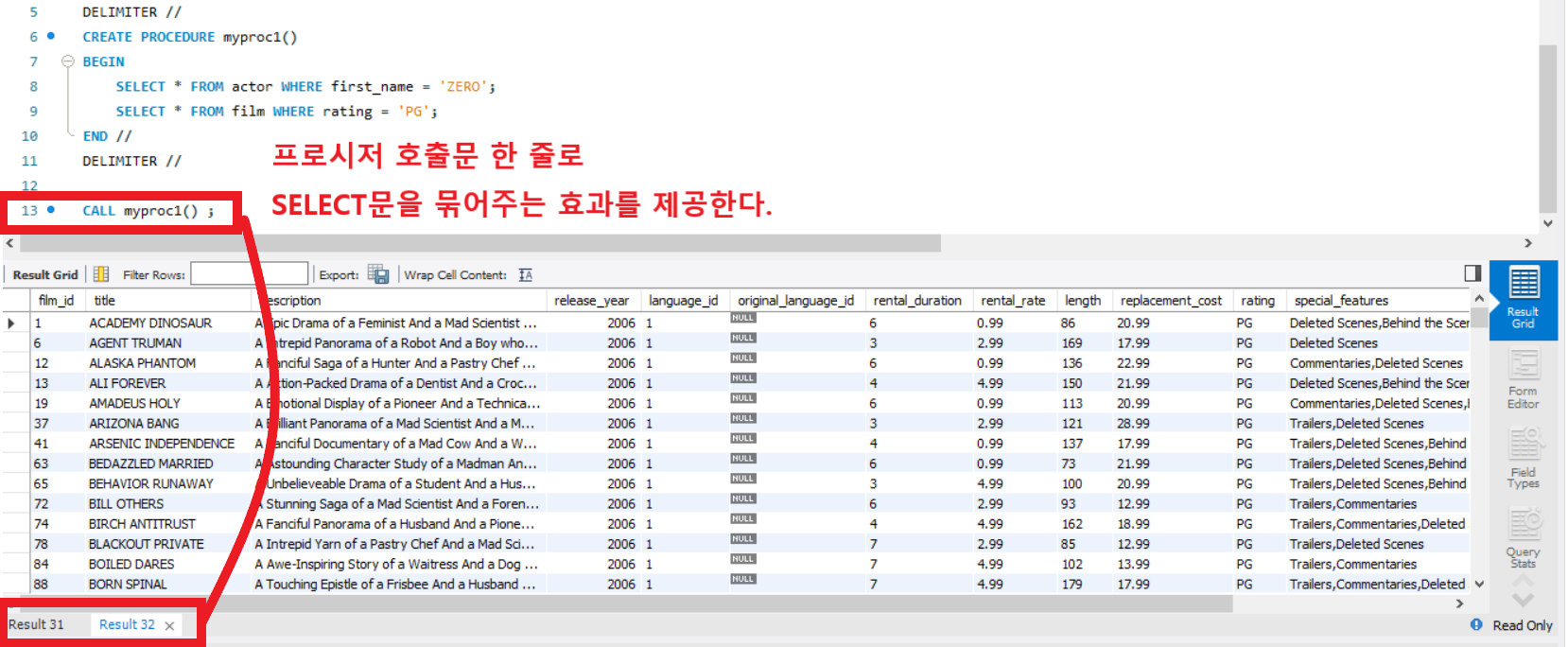
SELECT * FROM actor WHERE first_name = 'ZERO';
SELECT * FROM film WHERE rating = 'PG';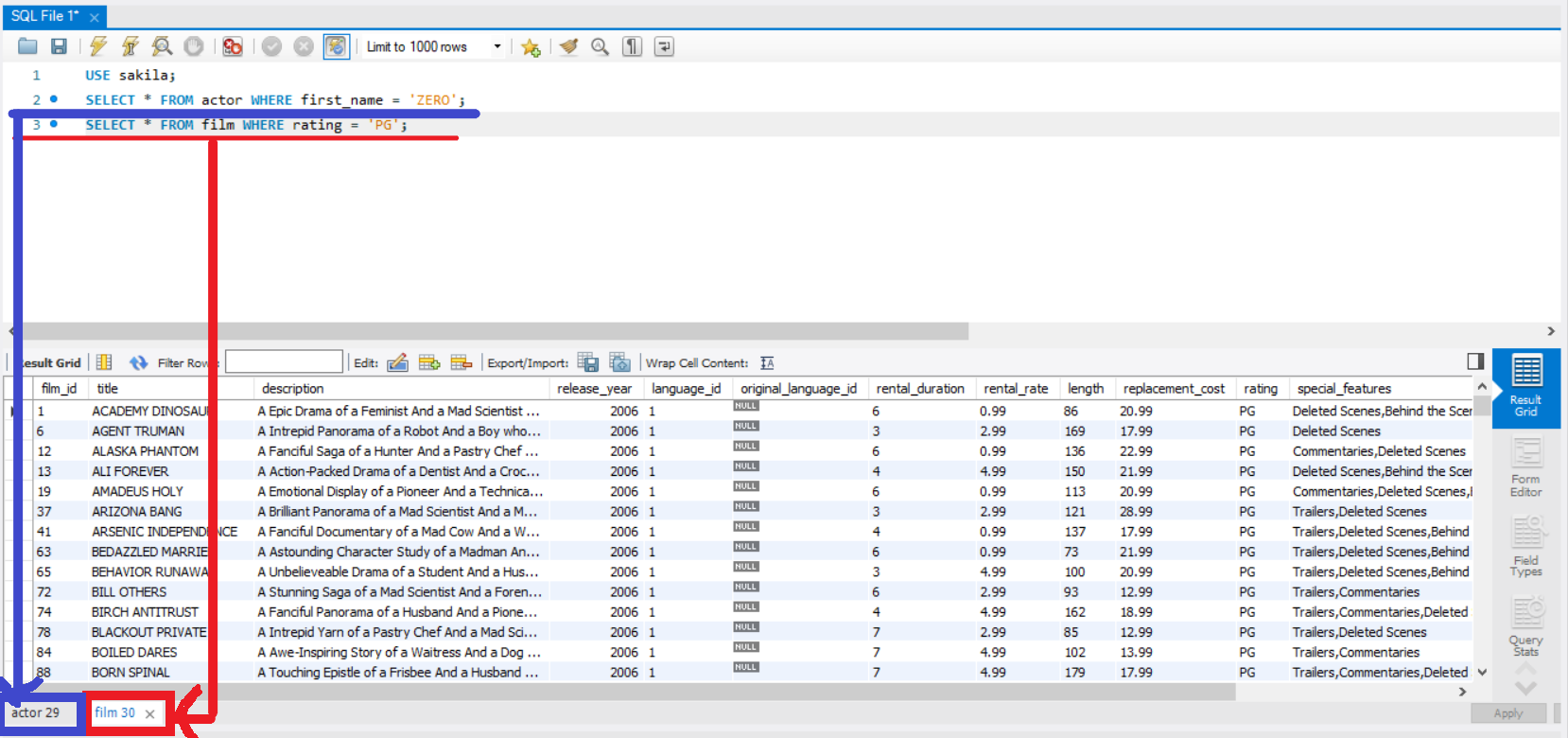
그리고 각각의 문장에 해당하는 두개의 결과가 조회됩니다.
하지만 이러한 경우 스토어드 프로시저를 사용하면 한줄로 조회가 가능해 집니다.
먼저 스토어드 프로시저를 생성해 보겠습니다.
DELIMITER //
CREATE PROCEDURE myproc1()
BEGIN
SELECT * FROM actor WHERE first_name = 'ZERO';
SELECT * FROM film WHERE rating = 'PG';
END //
DELIMITER ;여기서 DELIMITER란 '구분 문자'를 의미한다고 합니다. 뒤에 //가 나오면 기존의 세미콜론(;)을 대신한다는 의미입니다. 더 나아가서 CREATE PROCEDURE ~ END 까지를 하나로 묶어주는 효과를 가지는 정도로 생각하면 됩니다.
마지막엔 // 대신 세미콜론으로 마무리!!
위와 같이 프로시저를 생성후에 호출을 하면 아래와 같이 결과가 보여집니다.
3-2. 스토어드 프로시저 응용
위에서 잠깐 스토어드 프로시저를 통해 프로그래밍 언어와 비슷한 기능을 제공하기도 한다고 언급하였습니다. 물론 C언어 및 C# 등 우리가 생각하는 언어처럼 구현은 못합니다. 물론 데이터베이스 프로그램이기 때문에 그정도 퀄리티로까지 구현할 필요도 없습니다. 하지만 간단한 for문이나 if문 정도는 사용이 가능합니다. 한번 예시를 보겠습니다.
DELIMITER //
CREATE PROCEDURE myproc1()
BEGIN
DECLARE var INT; -- 선언
SET var = 100; -- var 변수에 100 입력
IF (VAR = 100) THEN
SELECT '100 이네요. 놀라워라!!';
ELSE
SELECT '100이 아닙니다. 아쉬워라!!';
END IF;
SELECT * FROM actor WHERE first_name = 'ZERO';
SELECT * FROM film WHERE rating = 'PG';
END //
DELIMITER //DBMS에서의 IF ELSE 문입니다. 우리가 흔히 사용하던 형식과는 다소 다르지만 뜻은 동일합니다.
위의 프로시저를 호출하면 아래와 같이 표시됩니다.

프로시저내의 if문이 수행이 되었고, 그에 따라서 참에 해당하는 동작이 실행된것을 알 수 있었습니다.
솔직히 아직까지 프로시저에서 프로그래밍 언어를 구현하라하면, 혹은 사용해보라하면 힘들 것 같습니다. 이 프로시저가 실제 실무에서는 어떻게 사용될지 정말 기대가 됩니다. 지금은 간단히 이렇게도 사용할 수 있다는 정도만 이해하고 넘어가도록 하겠습니다..ㅠ
4. 트리거(Trigger)
4-1. 트리거 개요
트리거는 흔히 총의 방아쇠로 알고 있습니다. DBMS에서의 트리거는 쿼리문에서 INSERT / UPDATE / DELETE 작업이 발생하였을때 어떠한 동작이 실행되는것을 뜻합니다. 또 다르게 생각해보자면 전에 배웠던 하드웨어인 Atmega에서 인터럽트와 비슷하다고 생각할 수 도 있을것 같습니다. 어떠한 조건(인터럽트)이 발생했을때 어떠한 동작(인터럽트 서비스 루틴)을 수행한다. 세부적으로는 다른점이 분명 존재하지만 비슷한점은 분명 존재하는것 같네요.
아래의 실습에서는 테이블의 특정 행을 삭제하고 삭제된 행을 새로운 테이블로 이동하는 과정을 트리거를 사용해서 실습해보겠습니다.
구체적인 순서는 아래와 같습니다.
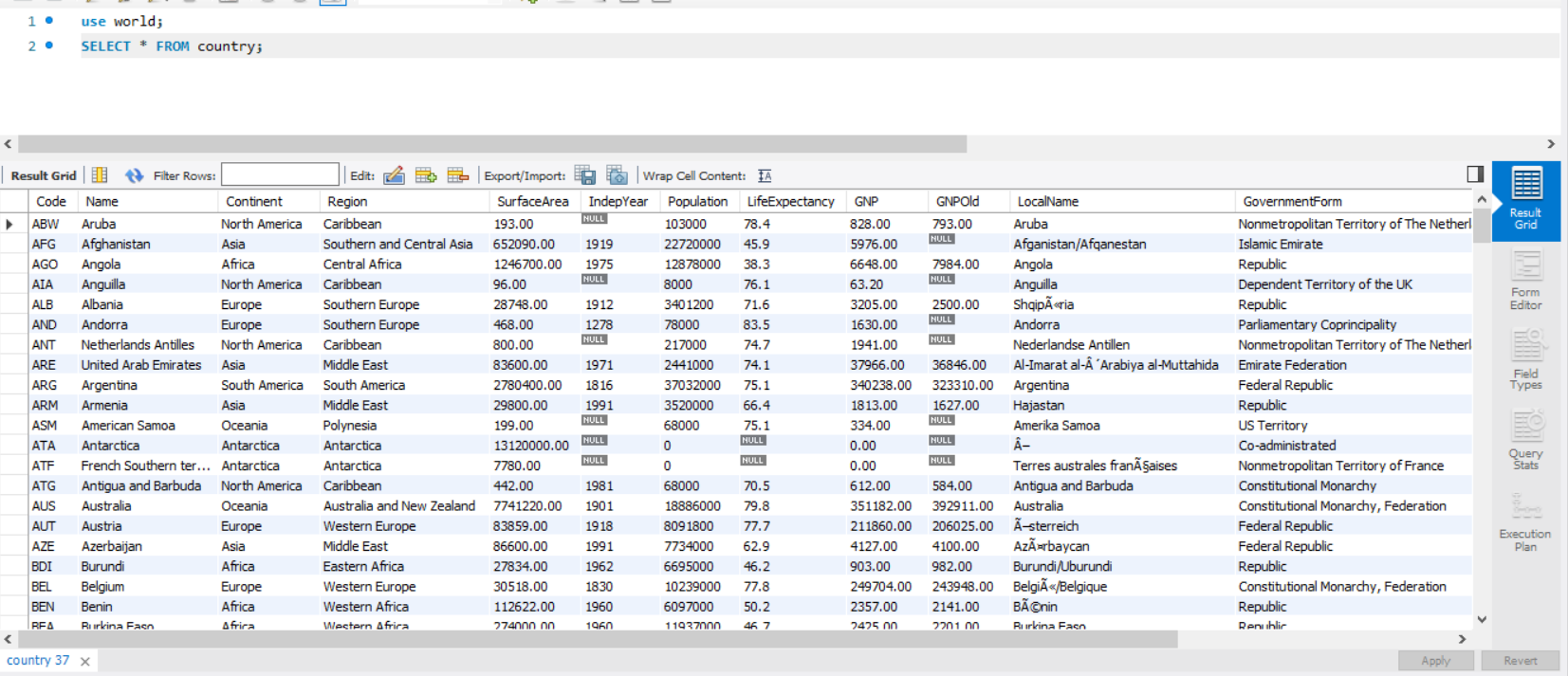
(1) world 데이터베이스에서 country의 테이블을 사용한다.
(2) delete_country라는 테이블을 만든다. (삭제된 행을 옮길 테이블)
(3) 특수 테이블(OLD)에서 데이터를 가져와서 새로운 테이블에 저장하는 트리거를 생성한다.
(4) country 테이블에서 continent열의 'Asia' 값을 가진 행만 삭제한다.
(5) country 테이블에서 Asia값이 가진 행이 사라졌는지 확인하고, delete_country테이블에 값이 추가된지 확인한다.
4-2. 트리거 실습
(1) world DB의 country 테이블 사용
(2) delete_country 테이블 생성
먼저 DESC 예약어를 통해 country의 열속성을 확인하겠습니다.
(새로 생성할 테이블에 포함시킬 열만을 선택하기 위해.. )
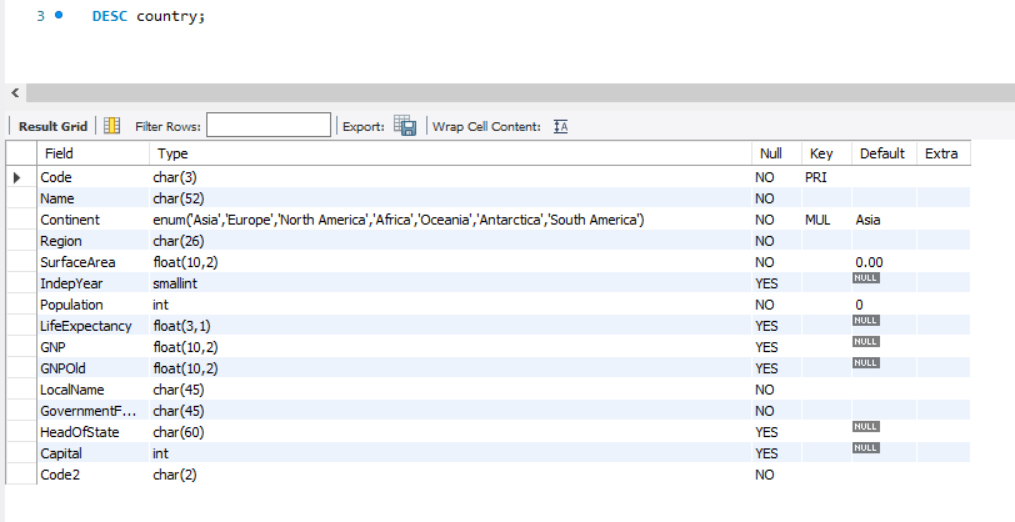
code, name, region, population 정도만 새로 생성할 테이블의 열로 사용하겠습니다.
CREATE TABLE delete_country(
code char(3),
name char(52),
region char(26),
population int,
delete_date date
);추가로 행이 삭제된 날짜를 저장할 delete_date 열을 추가하였습니다.
(3) 트리거 생성
DBMS내에서 모든 데이터는 삭제되기전에 잠시 특수한 테이블을 거쳤다가 삭제(DELETE) 됩니다.
따라서 특수한 테이블(OLD)의 데이터를 가져와서 새로만든 테이블에 저장하는 트리거를 생성하겠습니다.
DELIMITER //
CREATE TRIGGER trg_country
AFTER DELETE -- DELETE 트리거
ON country
FOR EACH ROW -- 문법 (예약어) 단순 암기 필요
BEGIN
INSERT INTO delete_country
VALUES (OLD.code, OLD.name, OLD.region, OLD.population, curdate());
END //
DELIMITER ;curdate()는 현재 날짜를 저장하는 예약어입니다.
위와 같은 형태를 delete Trigger (삭제 트리거)라고 부릅니다.
(4) country 테이블에서 특정 행 삭제

다음과 같이 간혹 테이블내의 행을 삭제하면 '1451' 에러 코드가 발생하곤 합니다.
이는 해당 테이블의 열값이 다른 테이블에 종속되어 있어서 삭제할 수 없는 경우인데요 이럴 경우에는 외래키를 체크 해제하고 수행하면 됩니다.
SET foreign_key_checks = 0;아직 외래키가 어떠한 의미인지 알지 못하기때문에 지금 당장은 이런식으로 대처하고 실습을 진행하겠습니다.ㅠㅠ
DELETE FROM country WHERE continent = 'ASIA';country 테이블에서 continent열의 값이 ASIA인 데이터를 모두 삭제하였습니다.
그럼 실제로 country 테이블에 데이터가 삭제가 되었고, 새로 생성한 테이블에 데이터가 들어갔는지 확인해보겠습니다.
(5) 신규 및 기존 테이블 데이터 확인
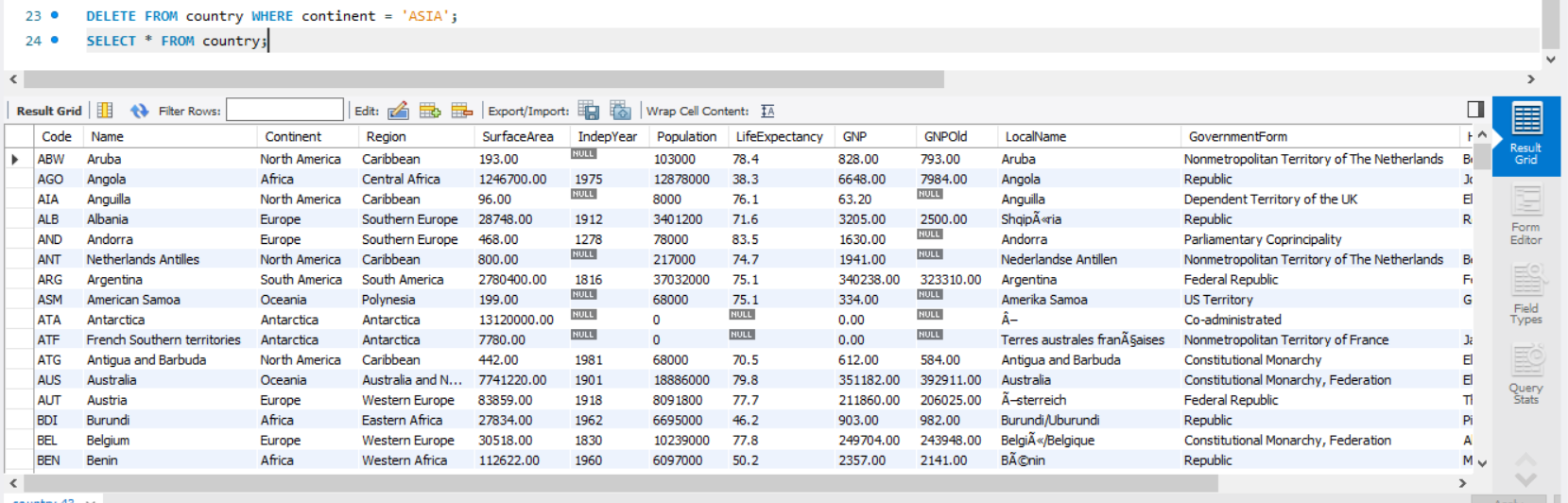
위 4-2. (1)의 사진과 비교했을때 Continent의 Asia값을 가진 데이터가 삭제된것을 알 수 있습니다.
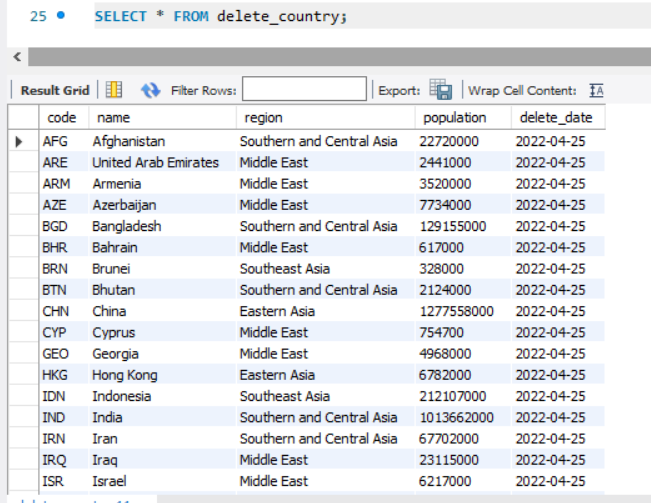
트리거를 통해 delete_country 테이블에 아시아 나라와 관련된 데이터만 저장된것을 확인 할 수 있습니다.
5. 백업 및 복원 (Export & Import)
5-1. 백업
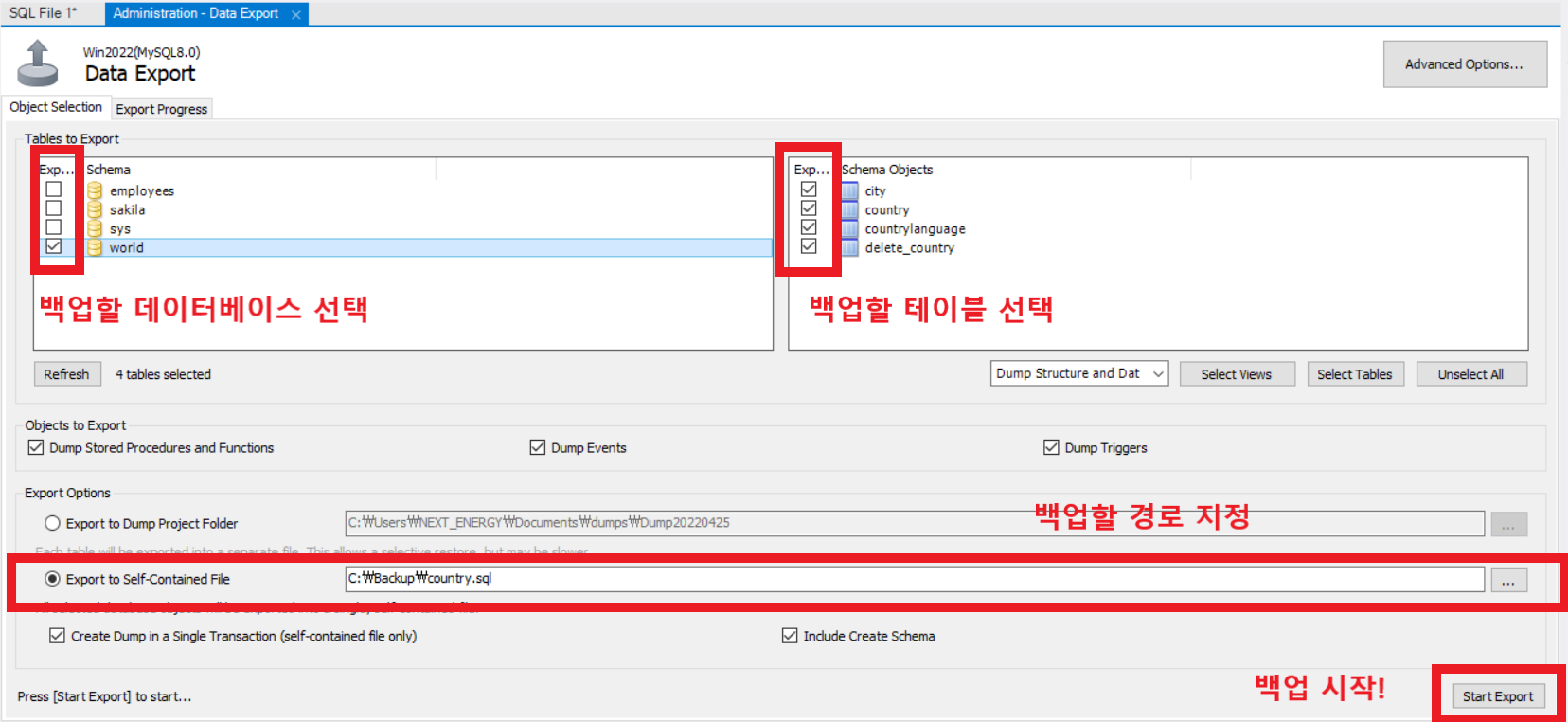
MySQL Wrokbench 좌측 메뉴창 → Administration 클릭 → "Data Export" 클릭
백업할 데이터베이스와 테이블을 선택하고 모든 체크박스를 선택
(체크박스에대한 의미는 별도로 검색을 해서 필요한 데이터 정보만 백업하도록 합니다.)
백업파일을 저장할 경로를 지정한 후에 우측 하단의 Start Export 클릭!!
5-2. 복원
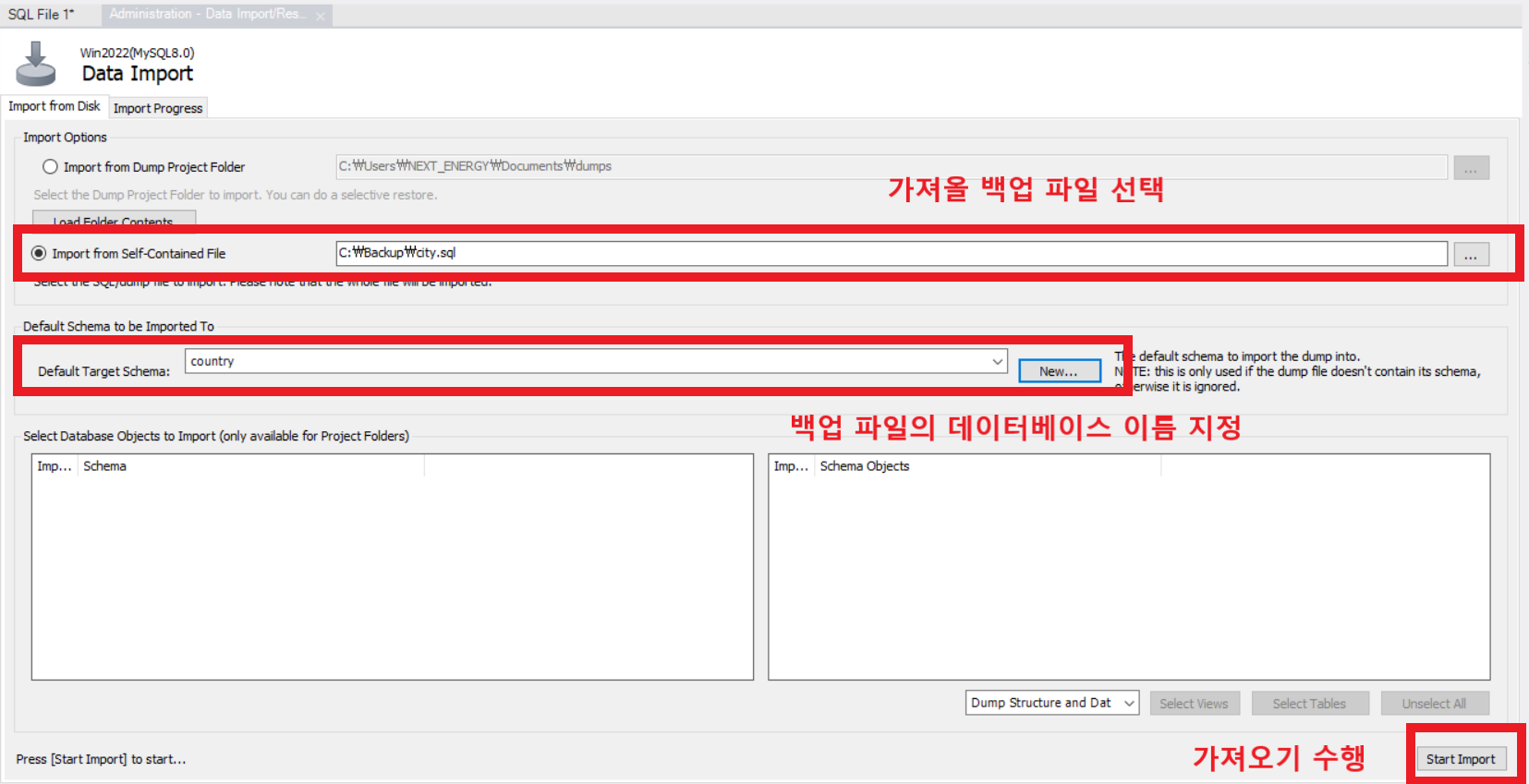
MySQL Wrokbench 좌측 메뉴창 → Administration 클릭 → "Data Import/Restore" 클릭
백업 파일을 선택한 후 가져올 백업 파일의 데이터베이스 이름을 지정합니다.
그리고 가져오기를 수행하면 복원이 완료 됩니다.
복원을 할때 데이터베이스의 이름을 새롭게 지정할 수 있습니다.
따라서 데이터베이스의 이름을 변경할 일이 있으면 이러한 방법을 사용해도 될 것 같습니다!!
좌측의 네비게이터 화면에 복원한 파일이 보이지 않는다면 새로고침을 해주세요!




댓글